
RESEARCH INTERESTS

My research takes advantage of recent advances in computational and natural language processing techniques to theorize and empirically trace how individuals and collectives communicate, search, create, innovate, problem-solve, coordinate, evaluate, judge, and decide. I study these patterns of individual and collective cognition in social systems ranging from small groups such as mountaineering expeditions and inventor teams to large-scale social systems such as online knowledge ecosystems and scientific disciplines. In so doing, my research brings an information theoretic, computational lens to classical questions within organization theory and economic sociology.
My research takes advantage of recent advances in computational and natural language processing techniques to theorize and empirically trace how individuals and collectives communicate, search, create, innovate, problem-solve, coordinate, evaluate, judge, and decide. I study these patterns of individual and collective cognition in social systems ranging from small groups such as mountaineering expeditions and inventor teams to large-scale social systems such as online knowledge ecosystems and scientific disciplines. In so doing, my research brings an information theoretic, computational lens to classical questions within organization theory and economic sociology.
PUBLICATIONS

Aceves, Pedro, and James A. Evans. “Human Languages with Greater Information Density Increase Communication Speed, but Decrease Conversation Breadth” Forthcoming, Nature Human Behaviour.
Human languages vary widely in how they encode information within circumscribed semantic domains (e.g., time, space, color, human body parts and activities), but little is known about the global structure of semantic information and nothing about its relation to human communication. We first show that across a sample of ~1,000 languages, there is broad variation in how densely languages encode information into their words. Second, we show that this language information density is associated with a denser configuration of semantic information. Finally, we trace the relationship between language information density and patterns of communication, showing that informationally denser languages tend toward (1) faster communication, but (2) conceptually narrower conversations within which topics of conversation are discussed at greater depth. These results highlight an important source of variation across the human communicative channel, revealing that the structure of language shapes the nature and texture of human engagement, with consequences for human behavior across levels of society.
Human languages vary widely in how they encode information within circumscribed semantic domains (e.g., time, space, color, human body parts and activities), but little is known about the global structure of semantic information and nothing about its relation to human communication. We first show that across a sample of ~1,000 languages, there is broad variation in how densely languages encode information into their words. Second, we show that this language information density is associated with a denser configuration of semantic information. Finally, we trace the relationship between language information density and patterns of communication, showing that informationally denser languages tend toward (1) faster communication, but (2) conceptually narrower conversations within which topics of conversation are discussed at greater depth. These results highlight an important source of variation across the human communicative channel, revealing that the structure of language shapes the nature and texture of human engagement, with consequences for human behavior across levels of society.
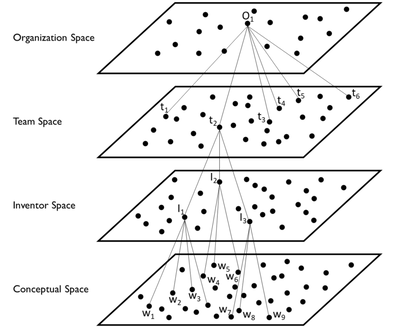
Aceves, Pedro, and James A. Evans. “Mobilizing Conceptual Spaces: How Word Embedding Models Can Inform Measurement and Theory within Organization Science" Forthcoming, Organization Science.
Word embedding models are a powerful approach for representing the multidimensional conceptual spaces within which communicated concepts relate, combine, and compete with one another. This class of models represent a recent advance in machine learning allowing scholars to efficiently encode complex systems of meaning with minimal semantic distortion based on local and global word co-occurrences from large-scale text data. Although their use has the potential to broaden theoretical possibilities within organization science, embeddings are largely unknown to organizational scholars, where known they have only been mobilized for a narrow set of uses, and they remain unlinked to a theoretical scaffolding that can enable cumulative theory building within the organizations community. Our goal is to demonstrate the promise embedding models hold for organization science by providing a practical roadmap for users to mobilize the methodology in their research and a theoretical guide for consumers of that research to evaluate and conceptually link embedded representations with theoretical significance and potential. We begin by explicitly defining the notions of concept and conceptual space before proceeding to show how these can be represented and measured with word embedding models, noting strengths and weaknesses of the approach. We then provide a set of embedding measurements along with their theoretical interpretation and flexible extension. Our aim is to extract the operational and conceptual significance from technical treatments of word embeddings and place them within a practical, theoretical framework to accelerate research committed to understanding how individuals, teams, and broader collectives represent, communicate, and deploy meaning in organizational life.
Word embedding models are a powerful approach for representing the multidimensional conceptual spaces within which communicated concepts relate, combine, and compete with one another. This class of models represent a recent advance in machine learning allowing scholars to efficiently encode complex systems of meaning with minimal semantic distortion based on local and global word co-occurrences from large-scale text data. Although their use has the potential to broaden theoretical possibilities within organization science, embeddings are largely unknown to organizational scholars, where known they have only been mobilized for a narrow set of uses, and they remain unlinked to a theoretical scaffolding that can enable cumulative theory building within the organizations community. Our goal is to demonstrate the promise embedding models hold for organization science by providing a practical roadmap for users to mobilize the methodology in their research and a theoretical guide for consumers of that research to evaluate and conceptually link embedded representations with theoretical significance and potential. We begin by explicitly defining the notions of concept and conceptual space before proceeding to show how these can be represented and measured with word embedding models, noting strengths and weaknesses of the approach. We then provide a set of embedding measurements along with their theoretical interpretation and flexible extension. Our aim is to extract the operational and conceptual significance from technical treatments of word embeddings and place them within a practical, theoretical framework to accelerate research committed to understanding how individuals, teams, and broader collectives represent, communicate, and deploy meaning in organizational life.

Evans, James A., and Pedro Aceves. 2016. “Machine Translation: Mining Text for Social Theory.” Annual Review of Sociology.
More of the social world lives within electronic text than ever before, from collective activity on the web, social media, and instant messaging to online transactions, government intelligence, and digitized libraries. This supply of text has elicited demand for natural language processing and machine learning tools to filter, search, and translate text into valuable data. We survey some of the most exciting computational approaches to text analysis, highlighting both supervised methods that extend old theories to new data and unsupervised techniques that discover hidden regularities worth theorizing. We then review recent research that uses these tools to develop social insight by exploring (a) collective attention and reasoning through content from communication; (b) social relationships through the process of communication; and (c) social states, roles, and moves identified through heterogeneous signals within communication. We highlight social questions for which these advances could offer powerful new insight.
More of the social world lives within electronic text than ever before, from collective activity on the web, social media, and instant messaging to online transactions, government intelligence, and digitized libraries. This supply of text has elicited demand for natural language processing and machine learning tools to filter, search, and translate text into valuable data. We survey some of the most exciting computational approaches to text analysis, highlighting both supervised methods that extend old theories to new data and unsupervised techniques that discover hidden regularities worth theorizing. We then review recent research that uses these tools to develop social insight by exploring (a) collective attention and reasoning through content from communication; (b) social relationships through the process of communication; and (c) social states, roles, and moves identified through heterogeneous signals within communication. We highlight social questions for which these advances could offer powerful new insight.
DISSERTATION
Title: “The Linguistic Relativity of Collective Cognition and Group Performance”
Committee: James A. Evans (Chair), John Levi Martin, Amanda Sharkey, Sameer Srivastava
The long-researched linguistic relativity hypothesis predicts that the structure of a person’s language influences their cognition. While this hypothesis has only been pursued in the context of how language affects individual cognition, my dissertation brings this argument into sociological territory by asking how the structure of language influences group performance. The idea is that the structural characteristics of a language can constrain some patterns of communication and collective cognition, while enabling others. I ask: 1) Can differences in language structure affect the performance of groups? If so, 2) what mechanisms account for this performance difference? To answer these questions, I trace the social interaction and collective cognition effects of a novel language structure attribute. I create estimates of information density, the average amount of conceptual information contained within words of a language, across the world’s languages. I then use computational, archival, and experimental methodologies to trace how the information density of a language affects the nature of social interactions and collective cognition as well as the way information flows through those interactions, thereby affecting group performance.
Committee: James A. Evans (Chair), John Levi Martin, Amanda Sharkey, Sameer Srivastava
- National Science Foundation DDRI Grant
- Winner, INFORMS/Organization Science Dissertation Proposal Competition, 2017
- Winner, Best Paper Award from the Managerial and Organizational Cognition division of AoM.
The long-researched linguistic relativity hypothesis predicts that the structure of a person’s language influences their cognition. While this hypothesis has only been pursued in the context of how language affects individual cognition, my dissertation brings this argument into sociological territory by asking how the structure of language influences group performance. The idea is that the structural characteristics of a language can constrain some patterns of communication and collective cognition, while enabling others. I ask: 1) Can differences in language structure affect the performance of groups? If so, 2) what mechanisms account for this performance difference? To answer these questions, I trace the social interaction and collective cognition effects of a novel language structure attribute. I create estimates of information density, the average amount of conceptual information contained within words of a language, across the world’s languages. I then use computational, archival, and experimental methodologies to trace how the information density of a language affects the nature of social interactions and collective cognition as well as the way information flows through those interactions, thereby affecting group performance.